
At first the structure of the text - the grammar - has to be be described. Many elementary text patterns, which are necessary for this, e.g. numbers, words etc. are already pre-defined in the TextTransformer as regular expressions. Several wizards are helping you to combine these expressions - tokens - to a complete grammar.
A sequence of expressions, which is expected in a text, will be recognized by the same sequence written in the grammar. E.g.
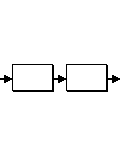
"Hello" "world"
would recogize the word "Hello" followed by the word "world".
Alternatives
are combined by '|'. E.g. the expression
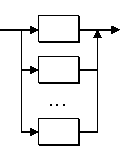
"all" | "nothing"
would recognize the words "all" and "nothing" in the text.
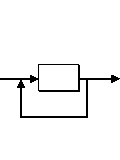
Options
are denoted by '?'. E.g.:
would recognize the word "perhaps", if it exists in the text.
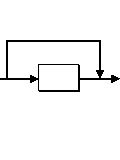
A repeat
is denoted by '+'. E.g.
digit+
would recognize a number consisting in an arbitrary sequence of digits, but at least in one digit (A digit can be defined as the character class of 0-9).
An optional repeat
is denoted by '*'. E.g.
digit*
would recognize the possible fractional digits of a number.
Wizards also are helping at the last step which is still necessary for a transformation program: the definition of actions, which determine, what has to be done with recognized parts of text.
The part of text, which was recognized at last can be accessed by the expression:
State.str()
This section of text either can be written directly into the output:
out << State.str();
or it can be stored e.g. in a string variable:
str s = State.str();
The correctness of your program finally can be tested stepwise by means of the integrated debugger at text examples.
 Deutsch
Deutsch
| Latest News |
|
05/18/26
Delphi2Cpp 2.7.0: Translation heuristics [more...] |
|
11/18/25
Delphi2Cpp 2.6.0: Delphi Interfaces [more...] |
|
"...Fantastic!!!! ... You have exceeded my expectations and I love your product. We will get a
lot of use out of it in the future for other projects." Charles Finley
xformix 23-02-07
|

I was extremely impressed with your components and tools. Not only extremely powerful but very professionally done and well documented, etc. Really quality work, congratulations
mouser (First Author, Administrator)
"Though we have not finished the conversion yet, I'm glad that we've found you and could transform Eurocap to C++ with the help of Delphi2CB and you. (And I'm also glad that we could help you to make Delphi2CB better😉)"
This website is generated from plain text with
[Minimal Website]

|
Minimal Website is made with TextTransformer

|
TextTransformer is made with Borland
C++Builder

|