The Java parser is a quite large project and a lot of work can be expected, to make a complete transformation program from it. The wizards of the TextTransformer can help greatly here.
As an example, at first the code for the generation of a parse tree shall be inserted in the project by the tree wizard. With the function table wizard then functions can be created by which the parse tree can be evaluated.
It is frequently recommendable to create a transformation program at first that simply copies the source files. With such a program the parser and the parse tree can be tested well: the program works correctly if the transformed files are identical with the source files. At the copy program then simple modifications can be made, the results of which can also be verified easily.
Who don't like to reproduce the following steps in detail can load the ready result made by the tree wizard also directly:
...\TextTransformer\Examples\Java\JavaTree.ttp
If you call the tree wizard in the HELP menu, then a choice appears for the manner, how the tree shall be created. You can leave this option.
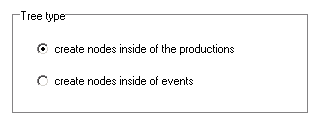
Next a choice appears for the node type and an entry field for the node name at first. node is elected as type and n is selected as name here:
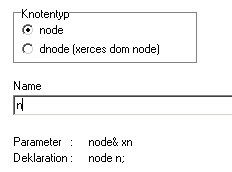
Below of the name field you can already see, how the node parameter in the parameter field and the node declaration in the text of the production will look like.
You leave the presetting on the next page of the wizard:

Then choose the complete option on the next page:

Three options can be chosen for the treatment of the literal tokens on the next page of the assistant.

For the copy program the undermost point must be selected. The semantic action IgLit which takes care that both a node for the ignored characters and a node for the recognized text are added to the tree, is then inserted after every occurrence of a literal token in the project.
The IgLit function then will be inserted on the element page..It looks like:
Name: IgLit // Ignorierter Text und Literal
Parameter: node& xnNode, const str& xs
Text:
{{
node n("IgLit");
xnNode.addChildLast(n);
n.add("IGNORED", xState.str(-1));
n.add(xs, xState.str());
}}
A sub-node with the label "Iglit" is added to the tree node xnNode and this sub-node gets the nodes for the ignored text and the text recognized by the token.
On the next page activate the check box: Pass parameters to all calls.

Then you can go to the last page and click on the Finish button.

After the results are shown you can close the Tree wizard by the Cancel button.
You can examine a generated tree after execution of the program with the start rule CompilationUnit, as demonstrated for the XML example in the variable inspector:
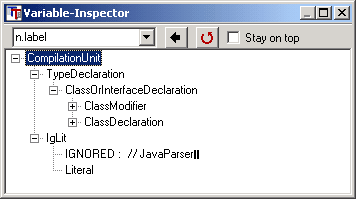
Remark: At the end of the start rule CompilationUnit explicitely the symbol EOF is set. So the wizard insertes an action for this symbol too:
EOF {{IgLit(n, "Literal");}}
In this last action the ignored text will be inserted in the tree, which follows on the last symbol of the Java grammar:
the comment: "// JavaParser"